ollama 本地安装部署
准备
- 良好的网络
- 下载 ollama
- windows 的话 建议 C 盘大亿点点,后面会用到,或者更建议修改模型存储位置
模式运行选择
- 在 windows 和 macOS下, 因为 docker 必须通过虚拟机才能 使用 docker,通过虚拟机就有明显的性能损耗,
请不要在这类系统下使用容器安装 - linux 下,因为 docker 更灵活且 ollamam 性能损失可以忽略,建议 容器部署
- 如果对性能有需求,且作为长期服务,请在 linux 下使用 vllm 部署,不用下面的文档
安装 ollama
windows 下安装需要注意
windows 建议配置 环境变量
OLLAMA_KEEP_ALIVE改为30m或者60m这样不用频繁载入模型OLLAMA_MODELS改为一个 大号的 SSD 固态盘,建议读写快的,路径为C:\data\ollama-modelsOLLAMA_ORIGINS改为http://127.0.0.1:*,http://localhost:*,http://172.17.0.1:*,http://host.docker.internal:*,http://192.168.*这样可以远程访问OLLAMA_HOST可选,可以修改为0.0.0.0:11434
Windows上的Ollama将文件存储在几个不同的位置。你可以查看它们
使用 <cmd>+R 键入内容 :
explorer %LOCALAPPDATA%\Ollama包含日志和下载的更新- app.log 包含来自GUI应用程序的日志
- server.log 包含服务日志
- upgrade.log 包含用于升级的日志输出
explorer %LOCALAPPDATA%\Programs\Ollama包含二进制文件 (The installer adds this to your user PATH)explorer %HOMEPATH%\.ollama包含模型和配置explorer %TEMP%包含一个或多个ollama*目录中包含临时可执行文件
需要不小的 C 盘空间就是
macOS 下安装需要注意
打开应用其实已经在后台 端口 11434 运行
OLLAMA_KEEP_ALIVE修改这个时间,可以防止重复挂载模型,缺点是更占用资源OLLAMA_HOST定义当前运行 服务 hostOLLAMA_ORIGINS跨域配置,这个需要点跨域知识,实在不会问生成式AI,大不了错几次OLLAMA_MODELS模型文件存储位置,这个选项可以更换下载位置
# 修改模型载入保留时间
launchctl setenv OLLAMA_KEEP_ALIVE "30m"
# 设置跨域主要是允许 容器使用
launchctl setenv OLLAMA_ORIGINS "http://127.0.0.1:*,http://localhost:*,http://172.17.0.1:*,http://host.docker.internal:*"
# 可选项设置跨域
launchctl setenv OLLAMA_ORIGINS "http://127.0.0.1:*,http://localhost:*,http://172.17.0.1:*,http://host.docker.internal:*,http://192.168.*"修改后,重启 ollama 服务,方法是 在状态栏点击退出,重新打开即可
说明文档见
macOS 上的 Ollama 将文件存储在几个不同的位置
~/.ollama/~/.ollama/models拉取的本地模型所在目录~/.ollama/logs本地日志
/Applications/Ollama.app程序文件夹~/Library/Preferences/com.electron.ollama.plist设置文件~/Library/Application\ Support/Ollama支持目录~/Library/Saved\ Application\ State/com.electron.ollama.savedState状态文件夹
容器安装 ollama
创建一个目录 ollama , 用来保存下载模型,以及运行日志等文件
mkdir ollama创建 ollama 容器 docker-compose.yml
# copy right by sinlov at https://github.com/sinlov
# Licenses http://www.apache.org/licenses/LICENSE-2.0
# more info see https://docs.docker.com/compose/compose-file/
networks:
default:
# Use a custom driver
#driver: custom-driver-1
services:
ollama-runner:
container_name: "ollama-runner"
image: ollama/ollama:0.1.33-rc5 # https://hub.docker.com/r/ollama/ollama/tags
ports:
- "11434:11434"
volumes:
- "./ollama:/root/.ollama"
# https://docs.docker.com/compose/gpu-support/
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]- 运行执行编排
# 启动编排,并常驻后台并
docker-compose up -d --remove-orphans
# 移除编排内所有容器
docker-compose down自定义启动 ollama 服务
这里在 windows powershell 环境下部署的, 因为好显卡在 windows,换其他环境请自己转换脚本
$env:OLLAMA_HOST="0.0.0.0:11433" ;
$env:OLLAMA_MODELS="$((pwd).Path)\ollama" ;
$env:OLLAMA_KEEP_ALIVE="30m"
# 这里留空即可
$env:OLLAMA_ORIGINS=""
## 如果需要远程访问,需要配置跨域
# https://github.com/ollama/ollama/issues/300 有详细讨论
$env:OLLAMA_ORIGINS="http://127.0.0.1:*,http://localhost:*,http://172.17.0.1:*,http://host.docker.internal:*,http://192.168.*"
# ollama 启动!!!
ollama serve这里说明一下,不同的 环境变量可以部署多套 ollama
- OLLAMA 支持的环境变量和用途见 源码
OLLAMA_KEEP_ALIVE修改这个时间,可以防止重复挂载模型,缺点是更占用资源OLLAMA_HOST定义当前运行 服务 hostOLLAMA_MODELS模型文件存储位置,这个选项可以告别 windows 爆掉 C 盘的问题OLLAMA_ORIGINS跨域配置,这个需要点跨域知识,实在不会问生成式AI,大不了错几次
使用 ollama 命令
ollame 本身是一个 管理大模型的工具
ollama cli 基本使用
list列出已经安装的模型pull拉取模型runrun 除了拉取模型,还同时将模型对应的交互式控制台运行了起来,不建议这么做,限定死了启动方式rm移除本地下载的模型ps查看当前硬件资源占用serve启动 大模型后台服务
额外说明
常用模型
- 模型格式
<name>:<num><arg>- name 为模型发布名称,后面
<num><arg>多少 B 表示模型有 多少 十亿 参数 - 参数规模规格为
B 十亿M 百万K 千 - 参数越多,所需 显存 越大,30b 左右差不多需要 20G 专有显存推理
- 参数多不代表准确,不过太小参数的 LLM 容易出现幻觉(瞎扯给结果)
- name 为模型发布名称,后面
tips: 7b 左右的专业模型,就可以勉强使用了,显卡不好的 20b 开始就明显表现为缓慢
## 多模态模型,可以混和图文处理
ollama pull llava:13b
ollama pull llava:34b
ollama pull bakllava:7b
## 文本大模型,只针对文本处理
ollama pull deepseek-r1:8b
ollama pull deepseek-r1:14b
ollama pull deepseek-r1:32b
ollama pull qwen2.5:7b
ollama pull qwen2.5:14b
ollama pull qwen2.5:32b
ollama pull qwen2:7b
ollama pull qwen:14b
ollama pull qwen:32b
# 翻译常用模型
ollama pull llama3.2:3b
ollama pull llama3.1:8b
ollama pull llama3:8b
# 70b 4090 24G 显存会不够必须集群跑
ollama pull llama3:70b
## 编码大模型
# 总结 commit
ollama pull mistral:7b
ollama pull lucianotonet/llamaclaude
# 代码提示
ollama pull qwen2.5-coder:7b
ollama pull qwen2.5-coder:14b
ollama pull qwen2.5-coder:32b
ollama pull codeqwen:7b
ollama pull codellama:7b
ollama pull codellama:13b
ollama pull codellama:34b
ollama pull deepseek-coder-v2:16b
ollama pull deepseek-coder:6.7b
ollama pull deepseek-coder:33b
ollama pull starcoder2:3b
ollama pull starcoder2:7b
ollama pull starcoder2:15bollama 拉取模型使用镜像
- 本地代理拉取
# ps
$env:HTTP_PROXY="http://"
$env:HTTPS_PROXY="http://"
$env:NO_PROXY="localhost,127.0.0.1,192.168.,localaddress,.localdomain.com"# 原镜像
ollama pull hf.co/{username}/{reponame}:latest
# 代理方式拉 https://hf-mirror.com
ollama pull hf-mirror.com/{username}/{reponame}:latest
# 比如 https://hf-mirror.com/Qwen/Qwen2.5-14B
ollama pull hf-mirror.com/Qwen/Qwen2.5-14B
ollama show --modelfile hf-mirror.com/Qwen/Qwen2.5-14B
# 比如 https://hf-mirror.com/Qwen/Qwen2.5-1.5B-Instruct-GGUF
ollama pull hf-mirror.com/Qwen/Qwen2.5-1.5B-Instruct-GGUF
ollama show --modelfile hf-mirror.com/Qwen/Qwen2.5-1.5B-Instruct-GGUFModelfile 自定义模型
查找 模型 配置例子
# 先需要拉取
ollama pull llama3:8b
ollama show --modelfile llama3:8b应用
本地 open-webui 使用ollama 服务
注意:这个模式下,ollama 和 外部编排容器运行的是冲突的, 建议 ollama 自己管理自己的容器编排,不要和外部掺和,就是这么设定的,阿门
- open-webui 文档
- open-webui 快速安装文档https://docs.openwebui.com/getting-started/quick-start/
- open-webui 环境变量配置https://docs.openwebui.com/getting-started/env-configuration/
注意: ollama 是一组后台服务, 使用
大模型的交互前端需要另外的部署,这里演示的是 open-webui
- docker-compose
- environment
WEBUI_SECRET_KEYwebui secret key 可以通过openssl rand -hex 16生成OLLAMA_BASE_URL这个根据实际情况配置HF_ENDPOINT可以加速模型下载
- volumes
./open-webui/data:/app/backend/data这个为 当前docker-compose.yml文件相对目录存储数据
- ports
11435:8080这个是 webUI 对外服务的 端口 设置 映射到11435,如果端口占用可以跟换network_mode: host如果开启,就是 8080,并且修改 OLLAMA_BASE_URL
- environment
services:
ollama-local-open-ui:
container_name: "ollama-local-open-ui"
image: ghcr.io/open-webui/open-webui:v0.3.21-ollama
# image: ghcr.io/open-webui/open-webui:v0.3.21-cuda
# image: ghcr.io/open-webui/open-webui:v0.3.21
pull_policy: if_not_present
environment: # https://docs.openwebui.com/getting-started/env-configuration/
OLLAMA_BASE_URL: 'http://host.docker.internal:11434' # 这里需要注意,这个地址连不上,使用完整 IP address 即可
HF_ENDPOINT: 'https://hf-mirror.com' # 从 https://hf-mirror.com 镜像,而不是https://huggfacing.co 官网下载所需的模型
WEBUI_SECRET_KEY: 'e2ac9c8f3462a9831b238601b8546807' # webui secret key
# PORT: '11435'
# network_mode: host
volumes:
- "./open-webui/data:/app/backend/data"
restart: unless-stopped # always on-failure:3 or unless-stopped default "no"
logging:
driver: json-file
options:
max-size: 2m- 运行执行编排
# 启动编排,并常驻后台并
docker-compose up -d --remove-orphans
# 移除编排内所有容器
docker-compose down使用 本地 open-webui
第一次需要注册账号
设置,进入设置
Settings- 修改语言
General->Language修改为你需要的语言
- 修改语言
设置,进入
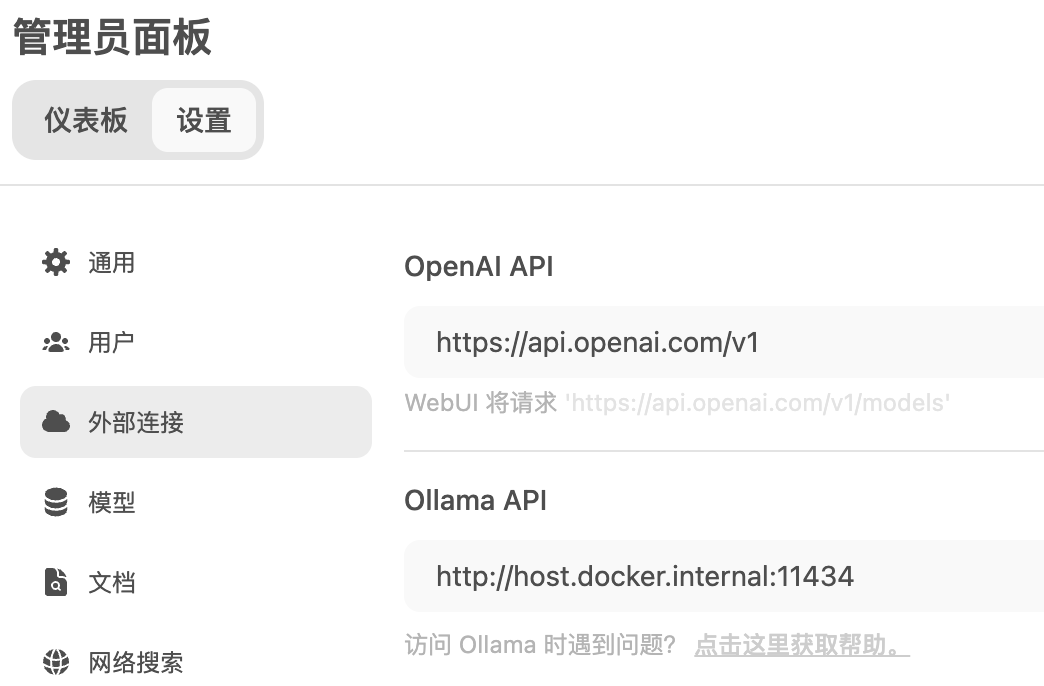
设置->管理员设置外部链接确认本地 ollama 链接http://host.docker.internal:11434可以正常使用- 也可以添加远程 ollama 链接
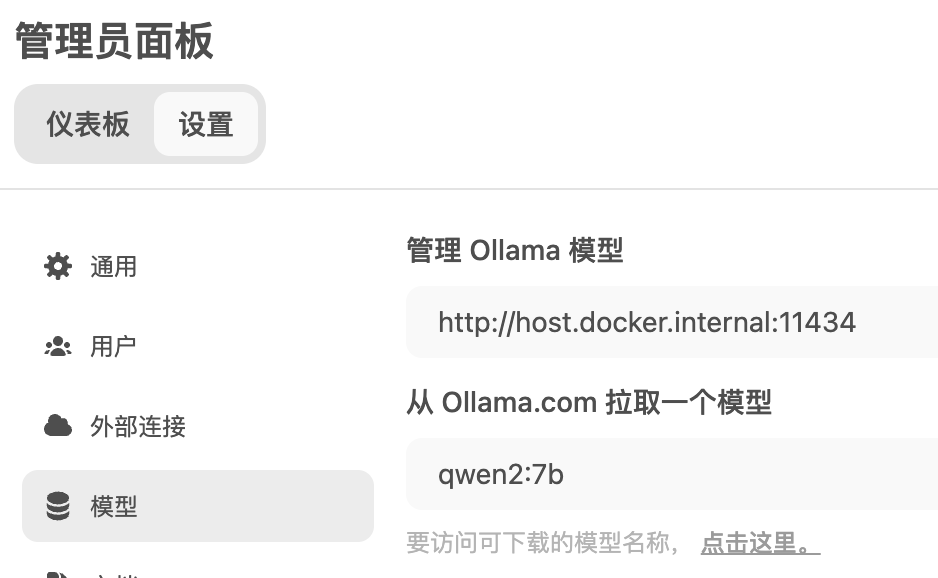
模型拉取
设置,进入
设置->管理员设置->模型
输入需要拉的模型
IDE ollama 扩展
查询扩展 https://github.com/ollama/ollama?tab=readme-ov-file#extensions–plugins,其中推荐试用
Continue
- Continue 代码助手,支持 vscode 和 JetBrains
opencommit
https://github.com/di-sukharev/opencommit
AI 总结代码,生成提交信息,支持本地模型
npm install -g opencommit
## pull model at local
# 高配设备推荐这个
ollama pull qwen2.5:14b
# 低配设备推荐这个模型
ollama pull llama3.2:3b
# 也可以拉其他模型
ollama pull llama3:8b
ollama pull mistral:7b
# 报错 Ollama provider error: Invalid URL
oco config set OCO_API_URL='http://127.0.0.1:11434/api/chat'
# 如果您在 docker/另一台具有GPU(非本地)的机器上设置了 ollama
oco config set OCO_API_URL='http://192.168.50.10:11434/api/chat'
## config
# set language
oco config set OCO_LANGUAGE=en
# set description
oco config set OCO_DESCRIPTION=true
# set model
oco config set OCO_AI_PROVIDER='ollama'
oco config set OCO_MODEL='qwen2.5:14b'
oco config set OCO_MODEL='qwen2.5:7b'
oco config set OCO_MODEL='mistral:7b'
oco config set OCO_MODEL='llama3.2:3b'
# 推理模型会把推理过程加到提交中,不建议使用
oco config set OCO_MODEL='deepseek-r1:14b'
# usage
git add <files...>
oco
# 跳过提交确认
oco --yes- 配置文件并使用oco config set命令进行设置 到 文件
~/.opencommit
OCO_AI_PROVIDER=<openai (default), anthropic, azure, ollama, gemini, flowise, deepseek>
OCO_API_KEY=<your OpenAI API token> // or other LLM provider API token
OCO_API_URL=<may be used to set proxy path to OpenAI api>
OCO_TOKENS_MAX_INPUT=<max model token limit (default: 4096)>
OCO_TOKENS_MAX_OUTPUT=<max response tokens (default: 500)>
OCO_DESCRIPTION=<postface a message with ~3 sentences description of the changes>
OCO_EMOJI=<boolean, add GitMoji>
OCO_MODEL=<either 'gpt-4o', 'gpt-4', 'gpt-4-turbo', 'gpt-3.5-turbo' (default), 'gpt-3.5-turbo-0125', 'gpt-4-1106-preview', 'gpt-4-turbo-preview' or 'gpt-4-0125-preview' or any Anthropic or Ollama model or any string basically, but it should be a valid model name>
OCO_LANGUAGE=<locale, scroll to the bottom to see options>
OCO_MESSAGE_TEMPLATE_PLACEHOLDER=<message template placeholder, default: '$msg'>
OCO_PROMPT_MODULE=<either conventional-commit or @commitlint, default: conventional-commit>
OCO_ONE_LINE_COMMIT=<one line commit message, default: false>支持 本地 .env 文件导入
jetbrains AI Git Commit
Support for OpenAI API.
Support for Gemini.
Support for DeepSeek.
Support for Ollama.
Support for Cloudflare Workers AI.
Support for 阿里云百炼(Model Hub).
Support for SiliconFlow(Model Hub).
本地使用 ollama 需要提前拉模型
## pull model at local
# 高配设备推荐这个
ollama pull qwen2.5:14b
# 低配设备推荐这个模型
ollama pull llama3.2:3bai-commit
使用ChatGPT、Gitmoji和常规提交使提交变得更容易
该工具维护有问题,建议测试后使用
# npm install -g ai-commit
# https://github.com/insulineru/ai-commit
# https://www.npmjs.com/package/ai-commit
# Set PROVIDER in your environment to ollam
ollama pull mistral:7b
# usage
ai-commit --PROVIDER=ollama --MODEL=mistralChatbox
AI 对话客户端 Chatbox
- 本地模型支持
- 一次使用一种模型
brew install chatboxCherry Studio
AI 对话客户端 Cherry Studio
- 本地模型支持
- 支持 助手 话题 翻译 ,不同业态使用
- 支持 三 模型同时使用
brew install cherry-studio- 该工具常用模型
## 助手
ollama pull deepseek-r1:8b
ollama pull deepseek-r1:14b
ollama pull deepseek-r1:32b
## 话题
ollama pull qwen2.5:7b
ollama pull qwen2.5:14b
## 翻译
ollama pull llama3.1:8b
ollama pull llama3.2:3b
ollama pull llama3:8b